The AWS incident that made us move everything to Kubernetes
On November 20th 2025, around 21:00, I suddenly started getting alerts that basically every Trackpac production service was down at the same time.
DNS (it’s always DNS), Lambda functions, APIs, databases, S3, queues. Basically the entire production environment instantly turned into a brick.
Everything.
Generally when everything breaks simultaneously, it’s usually not a small problem. At first we assumed it was just a temporary AWS issue or maybe some automated security flag that would get resolved within an hour or two…
It wasn’t.
AWS automatically detected suspicious account activity after an attempt was made to provision an unusually expensive EC2 instance that didn’t fit our normal usage patterns. To their credit, the detection worked almost immediately and there were no signs of broader infrastructure or customer data access.
The problem was the response.
Our AWS account and organisation were effectively frozen while the incident was under investigation. And because nearly our entire infrastructure lived inside AWS, the blast radius was enormous.
What followed was somewhere between two and four days of support tickets, verification loops, escalations and generally running in circles trying to get production access fully restored again. To be fair to AWS, I understand why they react aggressively to compromised accounts. If anything, I would probably be more concerned if they didn’t. But the incident exposed something we had not fully appreciated before:
We had accidentally built a platform where a single vendor lockout could take down literally everything we ran.
That was the moment we decided we wanted out. Not because Kubernetes is magically better. Not because self-hosting is trendy. Mostly because we no longer wanted a billing flag or account restriction to have the power to erase our infrastructure overnight.
So over the next months we slowly migrated everything from AWS serverless infrastructure to a self-managed k3s cluster running on Hetzner. Honestly, it ended up being one of the best infrastructure decisions we’ve made.
Now I can already hear the “but Hetzner is also a vendor” comments. And sure, technically that’s true. The difference is that we’re no longer deeply coupled to one giant ecosystem where networking, compute, databases, object storage, IAM, DNS and observability all disappear simultaneously if the account gets frozen. The entire cluster is reproducible from infrastructure-as-code, important data is replicated off-site, backups live outside the cluster, and moving providers again would mostly be annoying instead of existential. Which honestly feels like a much healthier failure mode.
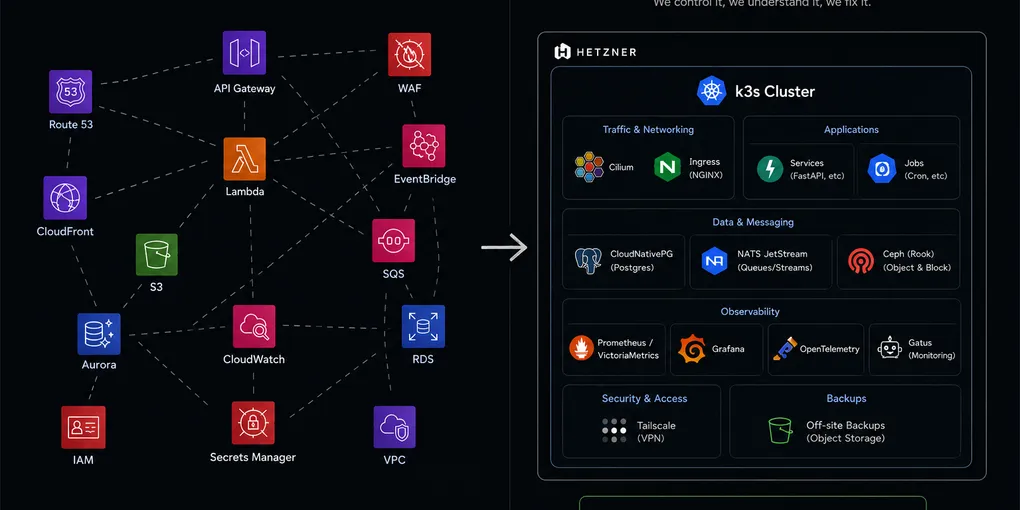
The original stack
The original platform was very AWS-native:
- Lambda functions running FastAPI and other on-demand workloads
- API Gateways
- Aurora PostgreSQL + MariaDB
- EventBridge scheduled jobs
- S3 object storage
- SQS queues
- IAM everywhere
- CloudWatch for logs
- and a bunch of other 3-character & creatively named services
Which sounds great on paper and honestly worked fine for a while.
Until you start noticing the trade-offs. Cold starts, fragmented observability, painful local development parity, stateful workloads becoming weirdly expensive, and networking abstractions stacked on top of even more networking abstractions.
And probably the biggest one: Lambda hides bad code surprisingly well. Because Lambda environments are disposable, you can get away with a lot of things that become very obvious once services become long-running containers.
Memory leaks? Suddenly visible once containers start getting OOMKilled.
Bad database connection handling? Connection exhaustion suddenly becomes very real.
Sluggish startup logic? Your pod is now stuck failing readiness probes.
Queries that technically work but are horribly inefficient? You notice pretty quickly once your workers get hogged and health checks start failing.
Moving to Kubernetes accidentally turned into a full codebase cleanup project. Which, in hindsight, was probably overdue anyway.
The cluster
We ended up building a relatively small HA k3s cluster on Hetzner to start with:
- 3 control plane nodes
- 3 worker nodes with NVMe storage
- Cilium for networking
- CloudNativePG for Postgres
- NATS JetStream to replace SQS
- Ceph (deployed with Rook) for storage (and S3!)
- Prometheus/VicotriaMetrics (still not fully decided) + Grafana for observability
- OpenTelemetry for measuring all kinds of programs and jobs
- Gatus for “is it up” monitoring and alerts
- Tailscale-secured Kubernetes and SSH access
Nothing particularly massive or exotic.
One tool that genuinely made this whole process much easier was hetzner-k3s. It handles a lot of the annoying bootstrap work and made the cluster surprisingly manageable without needing a gigantic Terraform codebase or spending days wiring infrastructure together manually.
I also use a bunch of Ansible playbooks for machine prep, Tailscale setup, upgrades and general maintenance tasks.
The interesting part is that despite moving away from “managed cloud”, the operational side actually became simpler in a lot of ways. Mostly because I now fully understand every moving piece.
Ceph was (and is) surprisingly nice
One thing I ended up liking way more than expected was running Ceph on the worker nodes. I’ve had some kubernetes experience before and always ran into weird PVC issues when rescheduling workloads. Probably because I was a noob…
The 3 workers all have NVMe storage and form a replicated Ceph cluster which now backs both object storage and persistent volumes. So S3-style storage is effectively inside the cluster itself. PVCs are no longer tied to individual nodes either, which makes rescheduling workloads much less painful.
Important data like everything in our object storage and database backups are also replicated off-site. CloudNativePG has an awesome automatic base backup and WAL plugin called the Barman Cloud Plugin. You just set up the base backup interval, enable WAL and provide S3 credentials and you’ve got Point-In-Time Recovery (PITR).
The nice thing about this setup is that scaling is pretty straightforward:
- If storage or compute ever becomes an issue, we can vertically scale the existing workers first
- If we just need more stateless compute, we can throw in extra smaller workers separately
Realistically we’ll probably never outgrow this cluster anytime soon… And that’s kind of the point.
The funny part about Kubernetes
I think people massively overcomplicate Kubernetes online.
If you read enough Reddit threads or other opinionated media you’d think you need:
- service mesh
- GitOps
- multi-region failover
- twelve operators
- three platform engineers
- and a CNCF certification shrine
In reality, ours is intentionally pretty boring. Maybe slightly less boring than it strictly needs to be, but still fairly sane.
Most things are just Helm charts and manifests in an IaC repository with good documentation. No ultra-fancy automation pipelines. No magical reconciliation systems constantly fighting each other. When something changes, I review it, apply it manually, verify it works, and move on with my life.
Turns out “boring and understandable” is a pretty solid infrastructure strategy.
Was it worth it?
Honestly, yes.
Our infrastructure savings for Trackpac alone are roughly 65% total. We still use some AWS services like SNS for messaging and SSM Parameter Store for secret management which are both considered non-critical and easily replaced.
But the bigger win was operational confidence. The infrastructure now feels owned instead of rented.
If something breaks, we can SSH into it, inspect it, understand why it failed and usually fix it ourselves.
And maybe most importantly, a single account restriction can no longer instantly take down literally everything we run.
Would I recommend everyone immediately leave AWS and self-host Kubernetes?
That’s honestly the wrong question. We didn’t leave because Hetzner is better than AWS or because self-hosting is some noble cause. We left because our blast radius was existential and now it isn’t. One compromised IAM user probably shouldn’t be able to erase everything you run. If yours can, that’s worth thinking about regardless of where you end up hosting.